
Agentmemory
#1 Persistent memory for Codex, Hermes, OpenClaw, Claude ++
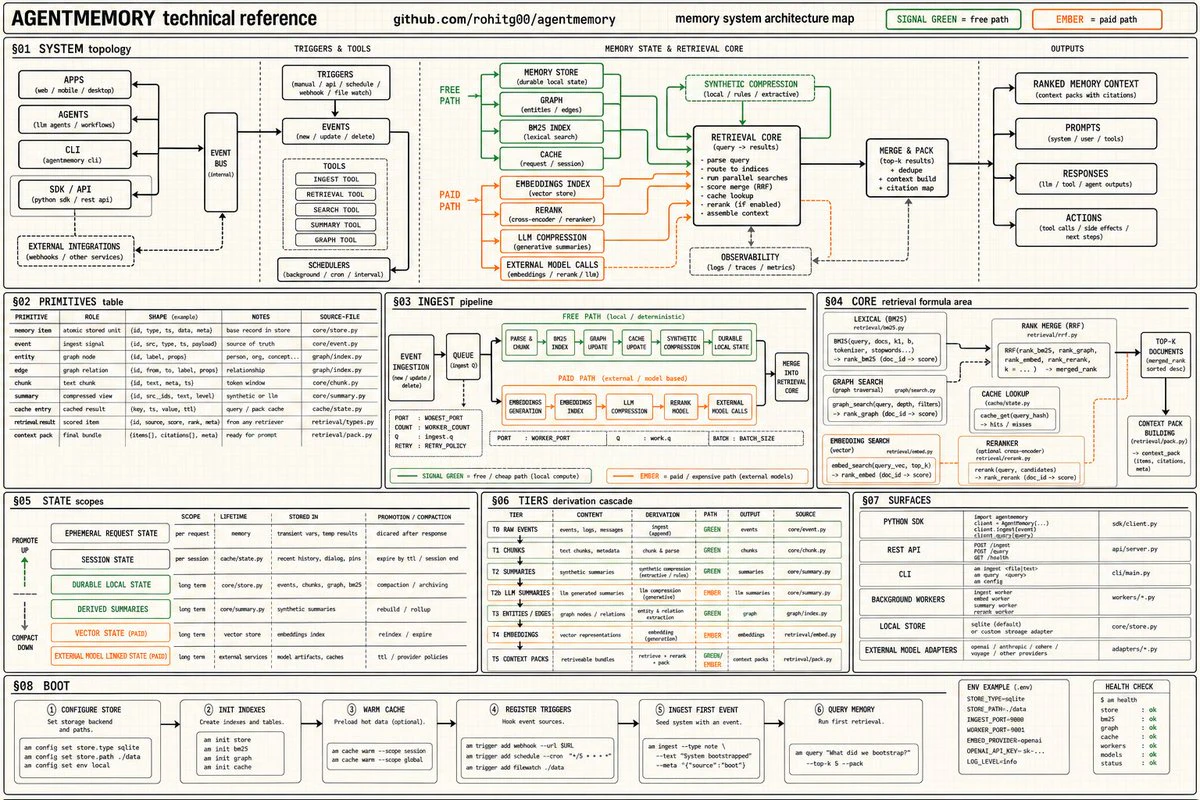
You can now give Hermes, Claude Code, and Codex infinite memory. Agentmemory is trending on GitHub with 5,000+ Stars. CLAUDE md dumps 22,000+ tokens into context at 240 observations agentmemory: 1,900 tokens. same observations. 92% less. At 1,000 observations, 80% of your built-in memories become invisible. agentmemory keeps 100% searchable. benchmarked on 240 real coding sessions → Up to 95% fewer tokens per session → 200x more tool calls before hitting context limits → 100% open source
AI Analysis
Agentmemory provides persistent, infinite memory for AI coding assistants including Codex, Hermes, Claude Code, and OpenClaw. It compresses over 22,000 tokens of observations into ~1,900 tokens (92% reduction) while keeping 100% of memories fully searchable, unlike built-in context that loses 80% visibility at 1,000 observations. Benchmarked on 240 real coding sessions, it delivers up to 95% fewer tokens per session and enables 200x more tool calls before hitting context limits. As a trending 100% open-source GitHub project with 5,000+ stars, it solves critical pain points of context window exhaustion and memory degradation in prolonged AI interactions, offering developers efficient, scalable memory management.
In 2025-2026, the AI agent ecosystem is exploding with wider adoption of Claude, GPT variants, and autonomous coding tools. Context window management and efficient memory have become core bottlenecks as agents handle longer sessions and more complex tasks. User demand for token-efficient solutions is surging amid rising API costs. This aligns perfectly with industry trends toward production-grade AI agents. Excellent Timing.
High. The solution is already developed, benchmarked, and released as a mature open-source GitHub project with significant traction (5k+ stars). Technical complexity of memory compression and search is solved. Development and operation costs are low for an OSS tool; no hardware supply chain or major compliance risks. Strong scalability potential within LLM ecosystems, though ongoing maintenance relies on community contributions.
Primary users: AI/ML engineers, software developers, and indie hackers building or using autonomous coding agents with Claude, Codex, or similar LLMs. Demographics: technically proficient, 25-45 years old, global distribution with high concentration in US, Europe, and Asia tech hubs. Industries: software development, AI tooling. TAM for AI developer tools exceeds $10B; SAM for agent memory/RAG solutions ~$1B. Core pain: context limits and memory loss in long sessions. High willingness to pay for premium support or hosted versions despite core OSS model.
Medium. Direct competitors: 1. MemGPT (memgpt.ai), 2. LangChain/LangGraph Memory modules (langchain.com), 3. Zep (getzep.com), 4. Mem0 (mem0.ai), 5. LlamaIndex (llamaindex.ai). Advantages: superior token compression (95% reduction) specifically benchmarked for coding sessions with Claude/Codex, full searchability guarantee, pure open-source with high GitHub traction. Disadvantages: newer entrant, potentially narrower scope than general RAG frameworks, lacks polished enterprise features or managed cloud service compared to some competitors.
Upgrade Pro to unlock full AI analysis
Similar Products

Adapt
The company brain that gets work done
▲ 124 votes

Tapfree for Chrome
Voice dictation that adapts to what’s on your screen
▲ 122 votes

React UI Kit V7
All the chat components you need. None of the complexity
▲ 115 votes

Onpilot
An AI workforce customized to your business
▲ 105 votes

Buddy AI Note
Your daily memo that turns notes into a plan
▲ 94 votes

Polygram
AI-native design and coding app to build mobile & web apps
▲ 81 votes