
Context.dev
One API to scrape, enrich, and extract the internet
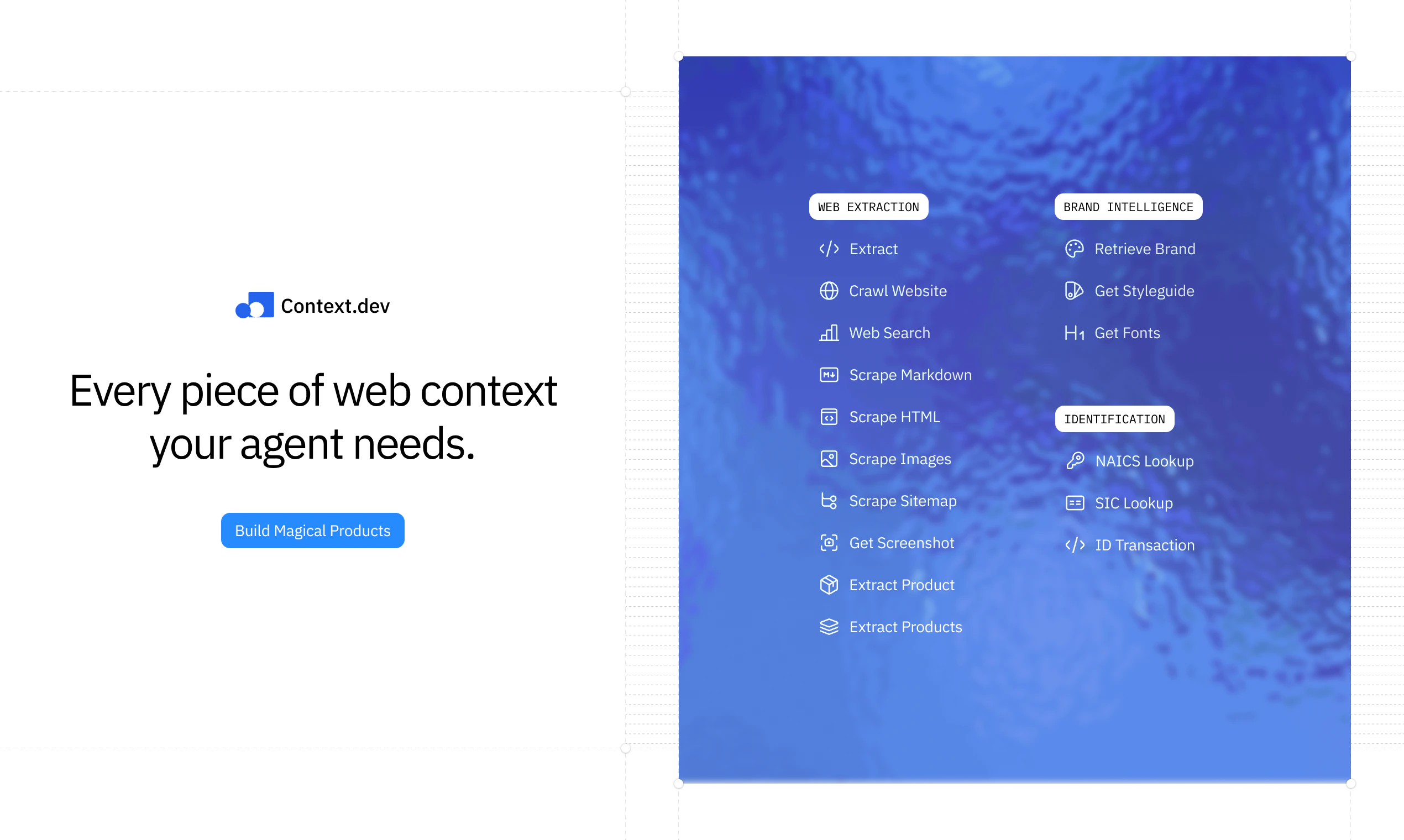
Context.dev is the web context API for AI products and agents. Scrape any URL, crawl sites, turn pages into LLM-ready Markdown, extract structured data into your own schema, capture screenshots, and retrieve logos, colors, fonts, styleguides, company data, and transaction enrichment through one API. YC-backed, no card required, and built so developers or coding agents can integrate in minutes.
AI Analysis
Context.dev is a unified web context API for AI products and agents. It enables scraping any URL, crawling websites, converting pages to clean LLM-ready Markdown, extracting structured data with custom schemas, capturing screenshots, and pulling design assets (logos, colors, fonts, styleguides) plus company and transaction data. It addresses key developer pain points like unreliable scraping, anti-bot measures, messy HTML parsing, and the complexity of integrating multiple tools. The value proposition is simplicity: one easy-to-integrate API (YC-backed, no credit card needed) that delivers production-ready internet context in minutes, empowering AI apps with real-world data.
The 2025-2026 period is highly favorable due to explosive growth in AI agents, autonomous workflows, and RAG/LLM applications that require fresh, structured web data. Web rendering and scraping technologies have matured, anti-bot challenges are well-understood, and demand for developer-friendly data APIs is surging amid AI adoption. Economic tailwinds for AI infrastructure and relaxed policies on data usage for training further support it. Excellent Timing.
Technical difficulty is medium-high (handling JS-rendered sites, anti-scraping, scale), but the YC-backed team has already solved core challenges with a working product. Operational costs involve cloud compute for browsers and storage, yet usage-based pricing offsets this. Compliance risks exist around data privacy (GDPR/CCPA) but are manageable with proper policies. Strong scalability via API model and proven quick developer integration. Overall rating: High.
Primary users are AI/ML engineers, indie developers, AI agent builders, and startups creating LLM-powered products (e.g., chatbots, research tools, automation). Industries: AI infrastructure, SaaS, enterprise automation. Geographic focus: global, with heavy adoption in US, Europe, and Asia tech hubs. TAM for AI data/API tools exceeds $10B; SAM for web scraping/enrichment APIs ~$2-3B; SOM for this service likely $100M+. Core pains: time wasted on brittle scrapers and poor data quality. High willingness to pay for reliable, low-maintenance API.
Medium. Direct competitors: 1. Firecrawl (firecrawl.dev) - strong in Markdown conversion and crawling; 2. Jina Reader (jina.ai) - focuses on LLM-friendly web reading; 3. Browserbase (browserbase.com) - browser automation and scraping; 4. ScrapeNinja or Apify (apify.com). Advantages: broader feature coverage (structured extraction, design assets, transaction enrichment, screenshots) in one API, developer-friendly (no card required, fast integration). Disadvantages: potentially higher pricing at scale and less established brand than older scraping services. Strong differentiation through AI-specific optimizations.
Upgrade Pro to unlock full AI analysis
Similar Products

Needle
The proactive GTM agent in Slack and Teams
▲ 244 votes

Adapt
The company brain that gets work done
▲ 124 votes

Tapfree for Chrome
Voice dictation that adapts to what’s on your screen
▲ 122 votes

Onpilot
An AI workforce customized to your business
▲ 105 votes

Buddy AI Note
Your daily memo that turns notes into a plan
▲ 94 votes

Polygram
AI-native design and coding app to build mobile & web apps
▲ 81 votes