
DramaBox by Resemble AI
AI turns scene descriptions into vocal performances
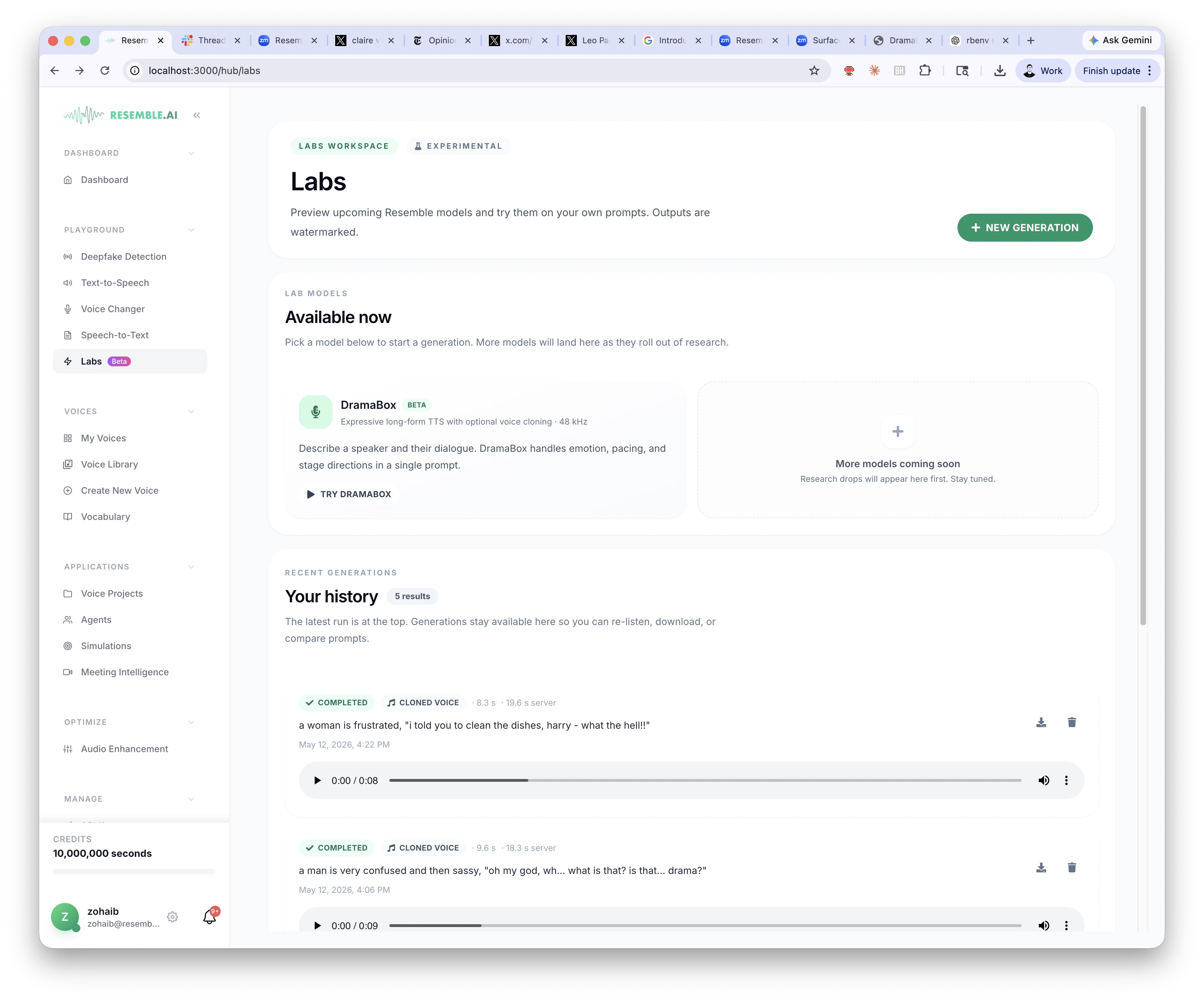
A TTS model should give you two things: an oscar-worthy performance and a verifiable signature to prove it's yours. DramaBox is the first to do both. Describe a scene the way you would to an actor, like 'a talk show host gasps in mock shock, bursts into laughter,' and the model interprets it as performance. Every output is watermarked with Resemble Watermarker. Open source, English-only for now, find it in your Resemble account or on Hugging Face.
AI Analysis
DramaBox by Resemble AI is a TTS model that converts scene descriptions (e.g., 'a talk show host gasps in mock shock, bursts into laughter') into expressive, actor-like vocal performances. Core features include nuanced emotional interpretation from natural language prompts and automatic watermarking via Resemble Watermarker for verifiable ownership. It is open-source, currently English-only, and available through Resemble accounts or Hugging Face. It solves key pain points of robotic, emotionless TTS outputs and lack of provenance in AI audio. The value proposition is delivering Oscar-worthy performances with built-in authenticity, empowering creators in media and content production with controllable, high-quality voice synthesis.
The 2025-2026 period is favorable as the generative AI audio sector matures rapidly, with surging demand for expressive TTS in content creation, gaming, and video production. Rising regulatory and ethical concerns around deepfakes make watermarking technology highly relevant. User needs are evolving toward more intuitive, performance-driven voice tools beyond basic text input. Economic tailwinds for AI tools and open-source adoption further support growth. This is Excellent Timing due to alignment with industry trends in emotional AI and content authenticity.
High. The model is already developed, open-sourced on Hugging Face, and accessible via Resemble accounts, proving technical viability. While training such emotional TTS models involves high ML expertise and compute costs, these are addressed as the product exists. Operational costs focus on inference scaling, with low supply chain risks but some compliance considerations for voice AI. Watermarking enhances scalability and trust. Strong potential for community-driven improvements and multilingual expansion.
Main segments: Content creators, YouTubers, podcasters, game developers, filmmakers, and indie AI/ML developers. Demographics: Tech-savvy professionals aged 25-45. Industries: Digital media, entertainment, advertising, and software. Geographic distribution: Primarily North America, Europe, and other English-speaking markets, with global developer interest. TTS market TAM exceeds $5B by 2026; SAM for expressive AI voice approx. $1B+. Core pain points: Difficulty achieving natural emotional performances without professional actors and proving content authenticity. High willingness to pay for premium Resemble platform features.
Medium. Direct competitors: 1. ElevenLabs (elevenlabs.io), 2. Play.ht (play.ht), 3. Murf.ai (murf.ai), 4. Bark by Suno (suno.ai), 5. Coqui TTS (coqui.ai). Advantages vs competitors: Unique actor-style scene description prompting, built-in watermarking for ownership (rare in competitors), and open-source access. Disadvantages: Limited to English (many competitors support multiple languages), potentially higher technical barrier for self-hosted open-source version compared to user-friendly SaaS interfaces, and less established brand presence than ElevenLabs in expressive TTS.
Upgrade Pro to unlock full AI analysis
Similar Products

Adapt
The company brain that gets work done
▲ 124 votes

Tapfree for Chrome
Voice dictation that adapts to what’s on your screen
▲ 122 votes

Onpilot
An AI workforce customized to your business
▲ 105 votes

Buddy AI Note
Your daily memo that turns notes into a plan
▲ 94 votes

Kosshi
Simple, fast outliner for Mac and iPhone.
▲ 90 votes

Polygram
AI-native design and coding app to build mobile & web apps
▲ 81 votes