
Firecrawl Research Index
An index for agents pushing the frontier of AI/ML research
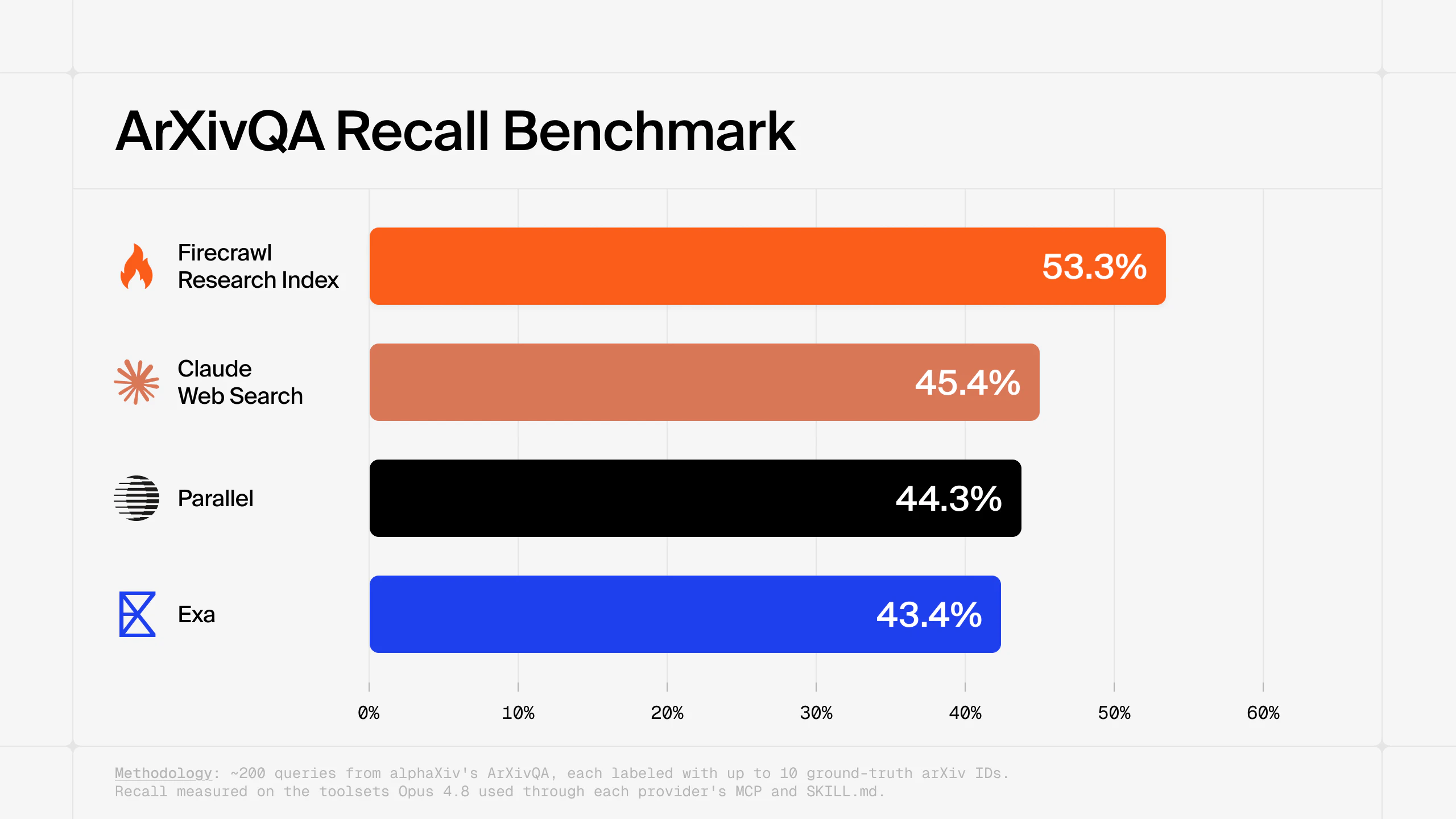
AI/ML research moves fast, and the work that matters is split between new papers and the code that implements them. Most search providers omit or misrank key papers, leaving you to review sources by hand without ever being sure you've caught everything. So we built an index for it. Firecrawl's index includes all 3M+ arXiv papers, as well as GitHub artifacts from top research repos, refreshed daily so agents always stay current.
AI Analysis
Firecrawl Research Index is a specialized, daily-refreshed database containing all 3M+ arXiv papers alongside GitHub artifacts from top AI/ML research repositories. It solves the critical pain point that AI/ML research advances rapidly with key insights split across papers and code, yet general search tools frequently omit or misrank vital sources, forcing manual and incomplete reviews. The unique value proposition is delivering a comprehensive, agent-optimized index that ensures AI agents and researchers always access the latest frontier developments without gaps. Built by the Firecrawl team, it combines structured academic content with practical implementations for superior research and development outcomes.
In 2025-2026, AI agent development is exploding with increasing demand for tools that enable continuous learning from cutting-edge research. Technology for indexing papers and code is mature, user demand from AI engineers is surging amid rapid model iteration cycles, and economic investment in AI infrastructure remains strong despite regulatory scrutiny. This product directly supports the trend toward more autonomous and knowledgeable agents. Excellent Timing.
Technical difficulty is moderate as the product builds upon Firecrawl's existing web crawling and data extraction capabilities to handle public arXiv and GitHub sources. Development and operation costs involve daily refresh compute and storage but are scalable via cloud services. Compliance risks are low since content is publicly available. The experienced team in AI data tools ensures good fit and high scalability potential. Overall rating: High.
Main target users are AI/ML engineers and researchers building autonomous agents, AI research labs, tech companies focused on frontier models (demographics: 25-40 years old tech professionals), and academic institutions. Primarily distributed in the US, Europe, and East Asia. TAM for AI knowledge tools exceeds $10B with SAM for research indices around $500M and SOM in the low tens of millions. Core pain points include incomplete research coverage and time wasted on manual aggregation. High willingness to pay via API subscriptions for tools improving agent performance.
Medium. Direct competitors: 1. Semantic Scholar (semanticscholar.org), 2. Papers with Code (paperswithcode.com), 3. Elicit (elicit.org), 4. Consensus (consensus.app), 5. Google Scholar (scholar.google.com). Advantages: Agent-centric design, seamless integration of papers with GitHub code artifacts, guaranteed daily freshness, and focus on comprehensive frontier coverage. Disadvantages: Newer product with potentially smaller brand recognition, less general academic breadth than incumbents, and may require technical integration for full agent use.
Upgrade Pro to unlock full AI analysis
Similar Products

Adapt
The company brain that gets work done
▲ 124 votes

Tapfree for Chrome
Voice dictation that adapts to what’s on your screen
▲ 122 votes

Onpilot
An AI workforce customized to your business
▲ 105 votes

Polygram
AI-native design and coding app to build mobile & web apps
▲ 81 votes

Mantel
Stop confusing your Claude Code sessions & terminal windows
▲ 72 votes

Stagent
Drive Claude Code through long tasks it would otherwise drop
▲ 58 votes