
MiniCPM-V 4.6
Ultra-efficient 1.3B vision-language model for mobile
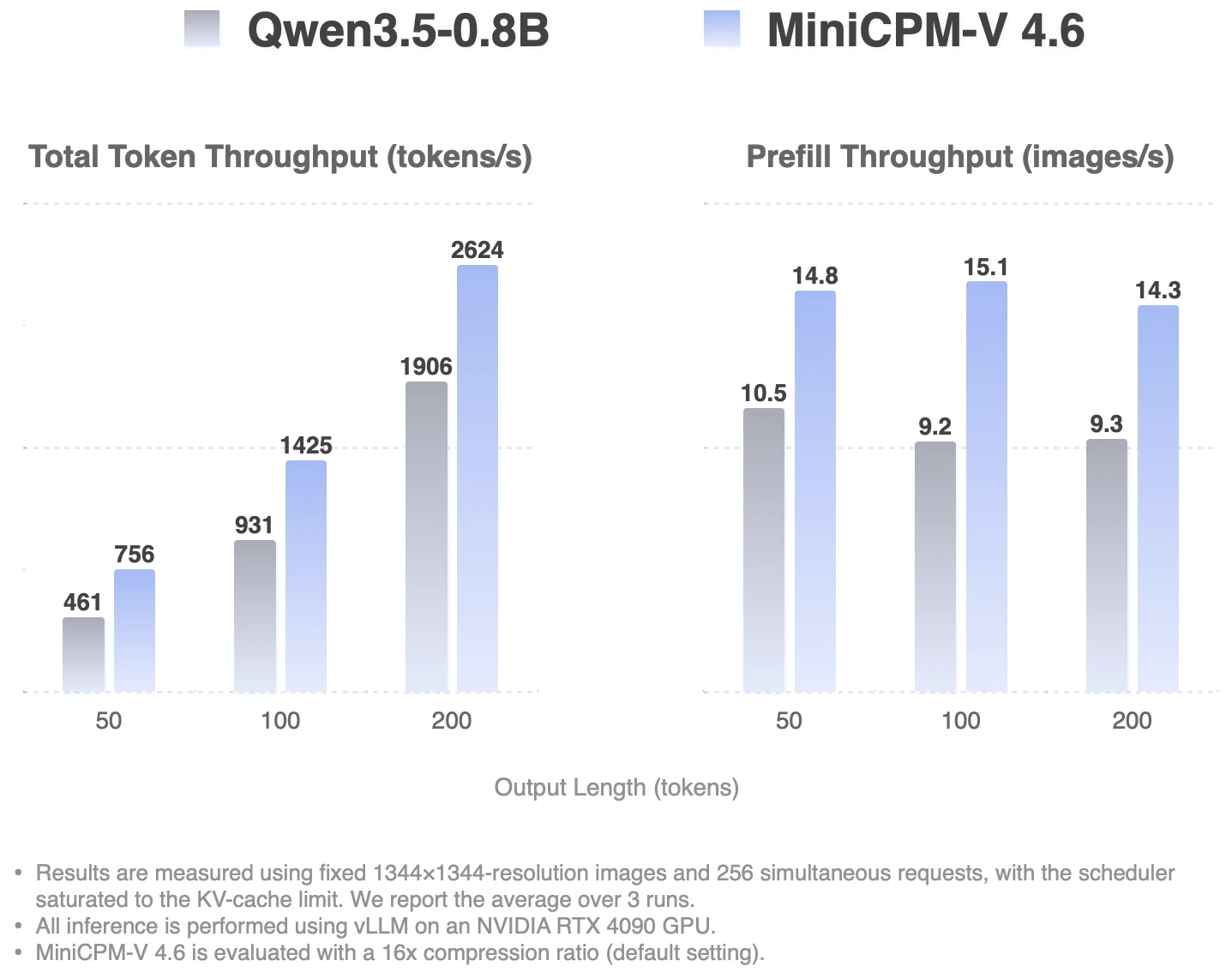
MiniCPM-V 4.6 is an open MLLM for image and video understanding on phones and consumer hardware, with mixed 4x/16x visual token compression, iOS/Android/HarmonyOS demos, and support for vLLM, SGLang, llama.cpp, and Ollama.
AI Analysis
MiniCPM-V 4.6 is an open-source 1.3B multimodal LLM optimized for on-device image and video understanding on phones and consumer hardware. Core features include mixed 4x/16x visual token compression for efficiency, ready-to-use iOS/Android/HarmonyOS demos, and broad backend support (vLLM, SGLang, llama.cpp, Ollama). It addresses key pain points of high compute costs, latency, and privacy risks in cloud-based AI by enabling powerful local multimodal inference. The value proposition is delivering capable, private, low-resource vision-language AI accessible to developers and users on everyday devices without specialized hardware.
2025-2026 trends strongly favor on-device and edge AI due to maturing mobile hardware, rising privacy regulations, demand for low-latency applications, and push for open-source AI amid geopolitical tensions. Technology for efficient small models is mature enough for practical deployment. This product aligns perfectly with the shift from cloud-only to hybrid/edge multimodal AI. Excellent Timing.
Technical integration is straightforward given pre-trained weights and multiple framework supports; development costs are low for adopters as it is fully open source. Compliance risks are minimal for open models, though commercial use terms should be checked. Excellent scalability on consumer devices with demonstrated mobile demos. Overall rating: High.
Primary users: AI/ML developers, mobile app creators, open-source enthusiasts, and researchers. Industries include consumer electronics, smartphone software, and edge AI solutions. Geographic focus: Global with strong adoption in China and North America. On-device AI TAM is estimated >$50B by 2026; SAM for open multimodal tools ~$5B; SOM for efficient sub-2B models in hundreds of millions. Pain points center on deploying capable vision AI locally without heavy resources. Willingness to pay is moderate for enterprise support, fine-tuning services or certified versions.
Competition Level: Medium. Direct competitors: 1. LLaVA (https://llava-vl.github.io/), 2. Microsoft Phi-3.5-Vision (https://github.com/microsoft/Phi-3), 3. MobileVLM (https://github.com/Meituan-AutoML/MobileVLM), 4. Alibaba Qwen2-VL (https://qwenlm.github.io/blog/qwen2-vl/), 5. Moondream (https://github.com/vikhyatk/moondream). Advantages: superior efficiency at 1.3B scale, actual mobile OS demos, advanced token compression for better speed/memory. Disadvantages: potentially lower benchmark scores on complex vision tasks versus larger competitors like Qwen2-VL. Strong differentiation in mobile-first open deployment.
Upgrade Pro to unlock full AI analysis
Similar Products

Adapt
The company brain that gets work done
▲ 124 votes

Tapfree for Chrome
Voice dictation that adapts to what’s on your screen
▲ 122 votes

Onpilot
An AI workforce customized to your business
▲ 105 votes

Buddy AI Note
Your daily memo that turns notes into a plan
▲ 94 votes

Polygram
AI-native design and coding app to build mobile & web apps
▲ 81 votes

Blop
Describe your app and Blop tests it and repairs broken tests
▲ 80 votes