
CatchAll by NewsCatcher
Build any dataset from the web. Filtered to your criteria.
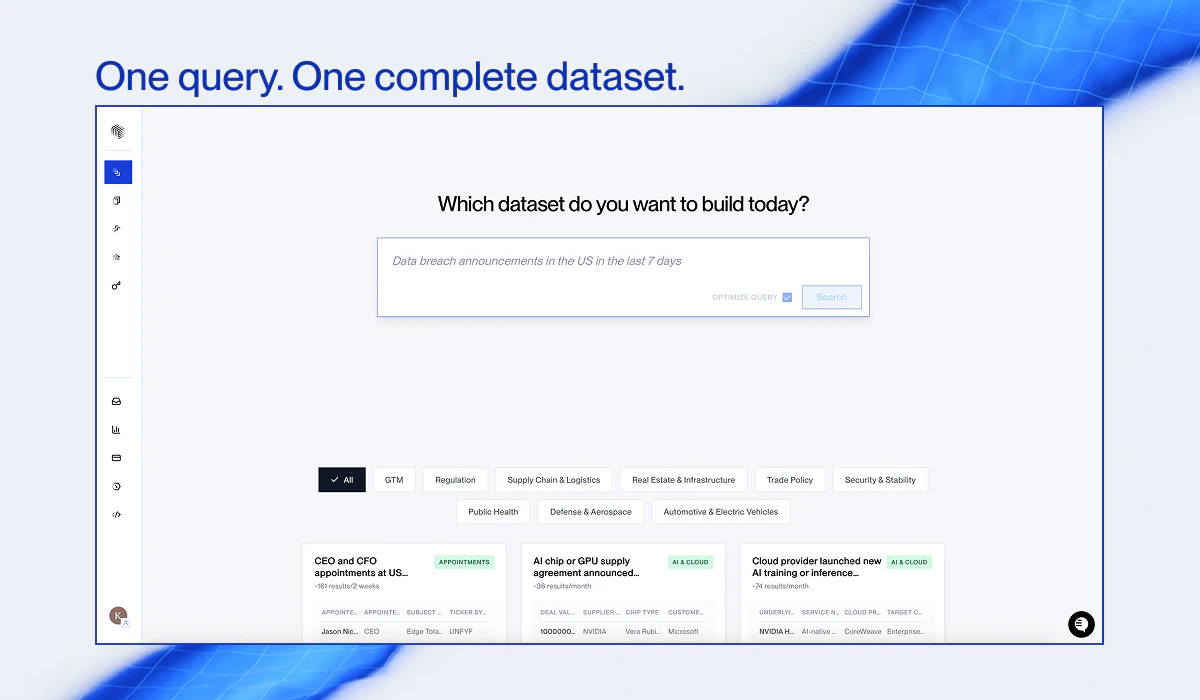
CatchAll is a web search API that builds structured datasets from the open web. Submit a query, and it scans thousands of web pages, validates every result, and returns clean, deduplicated records — not a ranked list of links, but a dataset of real-world events, ready for workflows and pipelines.
AI Analysis
CatchAll by NewsCatcher is a web search API that constructs structured datasets from the open web. Users submit a query; it scans thousands of pages, validates results, removes duplicates, and returns clean records of real-world events ready for pipelines instead of ranked links. Core features include custom filtering criteria, automated validation, and deduplication. It solves key pain points such as tedious manual scraping, handling unstructured or noisy web data, and integrating unreliable information into workflows. The value proposition is delivering high-quality, immediately usable datasets for developers and AI systems, saving time and improving data reliability for analytics and automation.
The current market timing is highly favorable. In 2025-2026, explosive growth in AI agents, LLMs, and automated workflows drives massive demand for high-quality structured web data. Technology for AI-powered extraction has matured, user needs are shifting from raw links to ready datasets, and economic pressures favor efficient data tools over manual labor. Regulatory focus on data quality and innovation further supports it. Excellent Timing.
Overall feasibility is Medium. Technical difficulty is notable for large-scale crawling, AI validation, and structuring diverse web content. Development and operation costs involve significant compute resources for scanning and processing. Compliance risks are prominent due to web scraping laws, copyright, and site terms. However, the NewsCatcher team's existing API experience aids execution, and cloud scalability is strong. Key risks are legal and operational at scale. Rating: Medium.
Main target segments: developers, data scientists, AI/ML engineers, and analytics teams (tech professionals, ages 25-45). Industries include artificial intelligence, data analytics, finance, research, and automation solutions. Geographic focus: primarily North America and Europe, with global reach. Estimated market size: TAM ~$8B+ (web data extraction/scraping market), SAM ~$1.5B (structured web dataset APIs), SOM ~$150M (queryable event datasets). Core pain points: time-intensive data collection and cleaning from web sources. Potential willingness to pay is high for reliable, time-saving API solutions (subscription model).
Competition level: Medium. Direct competitors: 1. Tavily (tavily.com), 2. Exa (exa.ai), 3. Firecrawl (firecrawl.dev), 4. Diffbot (diffbot.com), 5. Bright Data (brightdata.com). Advantages vs competitors: delivers fully cleaned, deduplicated structured event datasets rather than links or raw HTML; strong validation focus and suitability for any custom dataset. Disadvantages: newer entrant compared to established scraping platforms; may face higher costs or narrower use cases than generalist search APIs like Tavily or Serper; differentiation relies on execution quality of structuring pipeline.
Upgrade Pro to unlock full AI analysis
Similar Products
Auriko
Trading desk for LLM calls
▲ 332 votes

Adapt
The company brain that gets work done
▲ 124 votes

Tapfree for Chrome
Voice dictation that adapts to what’s on your screen
▲ 122 votes

React UI Kit V7
All the chat components you need. None of the complexity
▲ 115 votes

Onpilot
An AI workforce customized to your business
▲ 105 votes

Polygram
AI-native design and coding app to build mobile & web apps
▲ 81 votes